I have a SQL Table like this one:
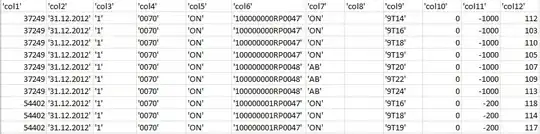
and I want the output to be like this:
Basically:
- replace duplicates with blanks but
- if col6 value is different from the previous row for the same col1 value, all the data fields should be included.
- col10 values are blank.
- col12 is removed.
I am struggling to create a query. I found this: CTE answer
and tried to run the following:
;WITH CTE
AS
(
SELECT DBA.s12.*,
ROW_NUMBER() OVER(PARTITION BY DBA.s12.col6 ORDER BY(SELECT 1)) rownum
FROM DBA.s12
)
SELECT
DBA.s12.col1,
DBA.s12.col2,
DBA.s12.col3,
DBA.s12.col4,
DBA.s12.col5,
DBA.s12.col7,
DBA.s12.col8,
DBA.s12.col9,
DBA.s12.col10,
DBA.s12.col11,
DBA.s12.col12,
CASE rownum
WHEN 1 THEN DBA.s12.col6
ELSE ''
END AS col6
FROM CTE
ORDER BY DBA.s12.col1;
but I get an error "Could not execute statement. Syntax error or access violation"
Can anyone shed some light on where my query has a syntax error/access violation or have a better method to extract the data?